
tg-me.com/nlp_stuff/360
Last Update:
مدلهای استدلالی (reasoning) چیست و چگونه ساخته میشوند؟
حتما این روزها بارها مدلهای استدلالی مثل DeepSeek R1 به گوش و چشمتون خورده. اگر هنوز دقیق نمیدونید این مدلها معنیشون چیه و کجا به درد میخورند، بیاید که دواتون پیش آقای سباستین راشکا (نویسنده کتاب Build a Large Language Model From Scratch) هست. ایشون یه بلاگ مشتی راجع به مدلهای استدلالی (همون reasoning) نوشته و مثل همیشه خیلی خوب داستان را شفاف کرده. این را داشته باشید تا منابع بعدی.
مواردی که در این بلاگ توضیح میده:
- تعریف مدل استدلالی چیه؟
- کجا باید از این مدلها استفاده کنیم؟
- پایپلاین پشت R1 چیه؟
- چهار روش اصلی برای ساختن و بهبود مدلهای استدلالی چیه؟
- نکاتی پیرامون مدل R1
- نکاتی برای توسعه مدلهای استدلالی با بودجه بسیار کم (حتی به اندازه دانشگاههای ایران کم ☺️)
اول میگه استدلال (reasoning) واسه وقتیه که سوالی را حل کنیم که نیاز به راهحل پیچیده و چندمرحلهای داره. مثلا پایتخت فرانسه کجاست اینجوری نیست ولی مثلا حل یه سوال فیزیک و ریاضی یا سوال acmای اینجوریه.
بعد میاد میگه سه جا خوب نیست اصلا از این مدلها استفاده کنیم:
- وقتی ما نیاز به سرعت و قیمت پایین داریم
- وقتی سوالهای دانشی (knowledge based) مثل همین پایتخت داریم چون این مدلها دچار هذیانگویی میشن
- سوالات ساده چون این مدلها مثل اکثر ما overthink میکنند
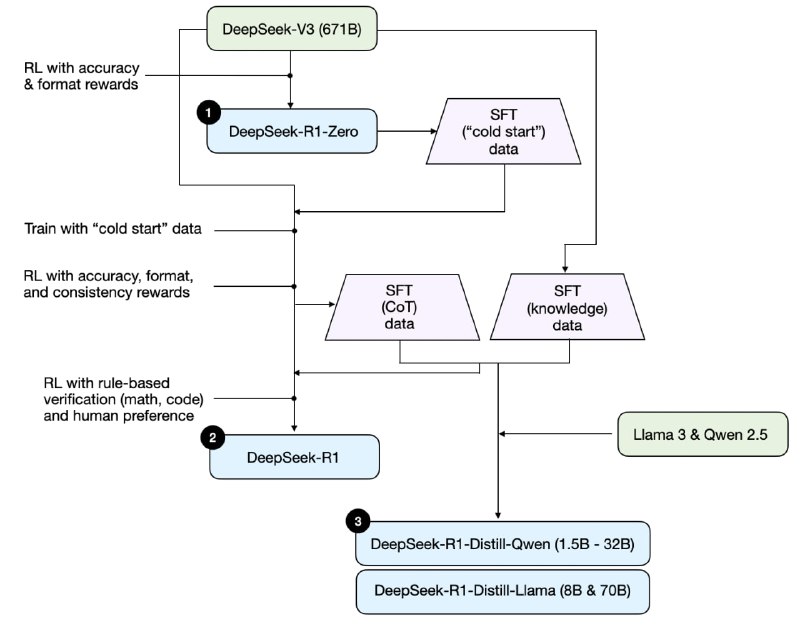
در ادامه میاد پایپلاین R1 را به شکل بسیار روان و سادهای توضیح میده. عکس ضمیمه یک کلیتی از این پایپلاینه. میگه deepseek سه تا مدل داده: DeepSeek-R1-Zero، DeepSeek-R1 و DeepSeek-R1-Distill.
اول. با مدل DeepSeek-V3 که سپتامبر بیرون دادن، با یک RL cold start (بدون SFT) شبیه همون RLHF با دو تا reward (یکی دقت و دومی فرمت به جای ترجیح آدمیزاد) آموزش میده؛ و مدل DeepSeek-R1-Zero را درست میکنه. بعد از همین مدل میاد یه داده SFT بزرگ درست میکنه. ریوارد دقت میاد از leetcode استفاده میکنه که نتیجه کد را مستقیما اجرا کنه و بگه!! فرمت هم میاد از یه سری تگ استفاده میکنه که دقیقا با همون فرمت جواب بده.
دوم. بعد دوباره همون مدل زبانی اولیه سپتامبری DeepSeek-V3 را با همین دیتا SFT که در مرحله قبل ساخته شده بود یه بار فاین تیون میکنه و دوباره همون RL رو میزنه. این بار ولی بهش consistency هم اضافه میکنه که مدل سر چند زبانه بودن پنالتی نزنه. از همین مدل دو تا دیتاست SFT میسازه که یکیش با اندازه ۶۰۰ هزارتا chaing of thoughts داره و دیگری با اندازه ۲۰۰هزارتا knowldegeای هستش. بعد میاد یه RL دیگه هم میزنه که دیتاش کد و ریاضی هست. اینجا مدل DeepSeek R1 معروف ساخته میشه.
سوم. از اون دوتا دیتای SFT هم برای آموزش مدلهای distill استفاده میکنه. البته اینجا distill مثل اون معروفه نیست، اینجا وقتی دیتای sft رو یه مدل قوی درست میکنه و مدل کوچیک (نیم الی ۷۰ میلیاردی) باهاش فاین تیون میشه، بهش میگن distillation.
خلاصه چهار تا روش برای تولید مدل استدلالی میگه:
- روش inference-time scaling: که از پرامپت و اینا استفاده میشه. منابع بیشتری لازمه. گرونتر هم درمیاد چون خیلی حرف میزنه.
- روش RL خالص مثل DeepSeek-R1-Zero
- روش SFT + RL مثل DeepSeek-R1
- روش SFT خالص با distillation: مثل DeepSeek-R1-Distill-Qwen
برای هر کدوم میزان کارایی رو توضیح میده و نهایتا میگه حالت سوم بهترین نتیجه رو میده ولی موارد دیگه هم چیزای جالبی بهمون یاد میده مثل اینکه RL خالی هم به استدلال مدل خیلی کمک میکنه.
در این بلاگ حدسهای خوبی هم راجع به اینکه O1 و mini-O1 هم چطور آموزش داده شدند میگه که O1 ترکیب سوم و اولیه و o1-mini روش چهارم هست.
در نهایت هم میاد نظراتش رو راجع به R1 vs O1 میگه: در کل شبیه هم هستند ولی R1 بهینهتر و ارزانتره که دلیلش رو این میدونه که دیپسیک بیشتر روی آموزش مدل وقت گذاشته ولی o1 روی inference-time رفته. و چون ما اندازه مدل o1 رو نمیدونیم خیلی مقایسه منصفانهای نخواهیم داشت. دربارهی هزینه هم میگه این ۶ میلیون دلار که معروف شده ترکیب DeepSeek-R1 (همون سپتامبریه که پایهی R1 هست) و R1 هستش ولی هزینه R1 رو دیپسیک مشخص نکرده.
برای موضوع آخر هم میگه کسایی که پول کم هم دارند خوبه برن سراغ Distillation: به لطف مقاله مفصلی که برای R1 نوشتند مشخص شد که این روش هم خیلی موثره. مثلا میگه مقالهای اومده یه مدل به نام Sky-T1 منتشر کرده که با ۴۵۰ دلار (۴۰ تومن) مدل ۳۲ میلیاردی را با ۱۷ هزارتا دیتای sft یه فاین تیون هدفمند کرده و در مواردی شبیه o1 عمل کرده!! موارد مهمی هم ادامش راجع به Journey Learning میگه که دیگه توی پست جا نمیشه :))
لینک پست:
https://sebastianraschka.com/blog/2025/understanding-reasoning-llms.html
#read
#blog
@nlp_stuff
BY NLP stuff
Share with your friend now:
tg-me.com/nlp_stuff/360